

本記事ではPythonの正規表現について解説します。
正規表現を使えるようになることで、高度な文字列処理を行えるようになります。
replaceやsplitメソッドでも文字列処理は行なえますが、正規表現ならより自由に行えるので、ぜひやり方を覚えてください。
本記事では、正規表現とは? 正規表現の代表的な使い方について解説していきましょう。
正規表現とは?
正規表現とは、文字列をパターン化した文字列で表現する方法です。
正規表現をPythonで活用することで以下のようなことができます。
- 文字列を検索する
- 文字列を置換する
- 文字列を削除する
こういったことは、Pythonに予め用意された関数やメソッドでも行えます。
しかし、正規表現を利用した方がより複雑な文字列処理が行えるのです。
たとえば、「3桁の数字の後に文字が2文字続く文字列のみ抽出する」といった場合に活用できます。
正規表現を覚えることで、あらゆる文字列処理が可能になり、機械学習にも応用できるようになります。
正規表現ではメタ文字を扱う
正規表現では特定パターンを書き表す場合に、「メタ文字」というものを使います。
メタ文字には次のような種類があります。
| メタ文字 | 意味 | 使用例 | 使用例に合致する文字列例 |
|---|---|---|---|
| . | 任意の文字 | 1.2 | 112,122,132 |
| ^ | 文字列の先頭 | ^a | at,am,aE |
| $ | 文字列の末尾 | a$ | ta,ma,Ea |
| * | 0回以上繰り返す | ac* | a,ac,acc,accc |
| + | 1回以上繰り返す | ac+ | ac,acc,accc |
他にも数多くのメタ文字があり、とても紹介しきれないので、その他のメタ文字に関しては、Pythonの公式ページを御覧ください。
Pythonの正規表現ではre モジュールを使う
Pythonで文字列処理を行う場合、「re モジュール」を使う必要があります。
re モジュールを使うことで、正規表現で必要な検索や置換などのメソッドを活用することが可能です。
たとえば、次のようなメソッドが存在します。
- match():文字列が特定パターンとマッチするか判定する
- search():文字列に特定パターンが含まれているか検索する
- group():特定パターンにマッチした文字列を返す
- start():特定パターンにマッチした文字列の開始位置を返す
- end():特定パターンにマッチした文字列の終了位置を返す
この内、match()、search()、group()は特によく使います。
Pythonの基本的な正規表現の使い方
Pythonの基本的な正規表現の使い方を紹介しましょう。
以下の項目に分けて解説します。
- 正規表現で特定の文字列があるか調べる
- 正規表現で電話番号を調べる
- 正規表現でURLを調べる
正規表現で特定の文字列があるか調べる
まずは正規表現で特定の文字列があるか調べる方法です。
○コード例
import re result = re.search(r'banana', 'banana apple watermelon yuzu') print(result.group())○実行結果
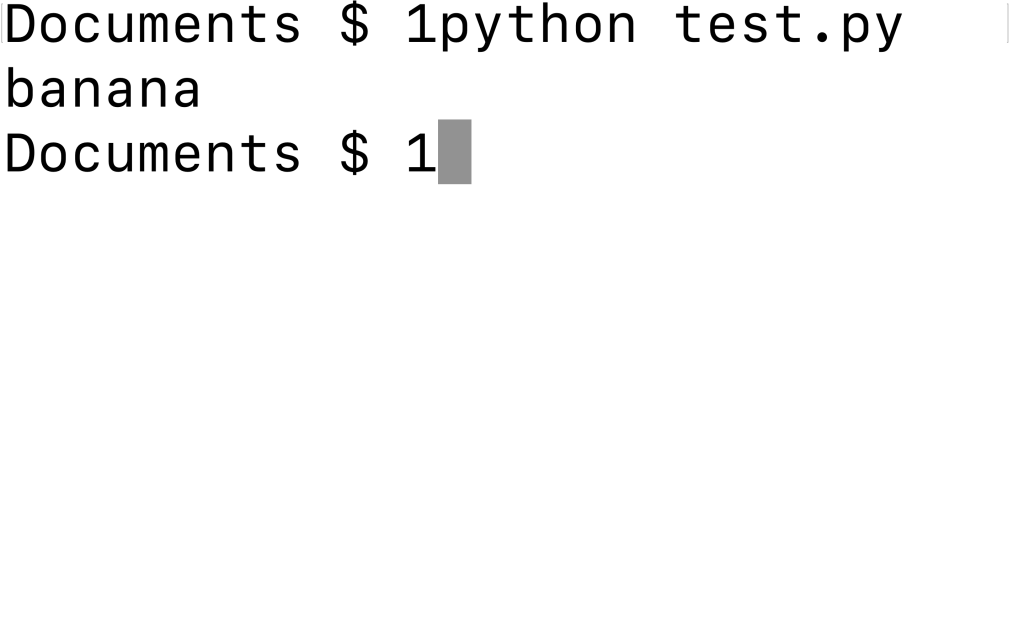
上記のコードでは、まず「import re」と記入しています。
re モジュールを読み込むことで正規表現を使えるようにします。
searchメソッドの第一引数に、文字列パターンを指定します。
第二引数に、チェックしたい文字列を指定します。
今回は「banana」という文字列が「banana apple watermelon yuzu」の中にあるか調べています。
その後groupメソッドによって、マッチした文字列が表示されます。
これが正規表現の基本になります。
正規表現で電話番号を調べる
続いて、正規表現で電話番号を調べる方法をみていきましょう。
○コード例
import re numbers = "111-1111-1111"; if re.match("\d{3}-\d{4}-\d{4}", numbers): print("これは電話番号の可能性があります") else: print("これは電話番号ではありません")○実行結果

matchメソッドを使って、特定パターンに文字列がマッチしているか調べます。
第一引数に特定パターンを指定し、第二引数にチェックしたい文字列を指定します。
「\d{3}」はメタタグの一種です。
「\d」は「数値」という意味で「{3}」はそれが「3回繰り返される」という意味です。
つまり、数値が3回繰り返された場合のみマッチするということです。
「\d{4}」も同様で、数値が4回繰り返された場合のみマッチします。
今回は「111-1111-1111」でしたので、特定パターンにマッチします。
matchメソッドは、マッチする場合「True」を返すため、「これは電話番号の可能性があります」と表示されます。
このようなやり方で、文字列が電話番号か調べることが可能です。
正規表現でURLを調べる
最後に、正規表現でURLを調べる方法を紹介しましょう。
○コード例
import re url = "https://www.google.com/"; if re.match("https?://[\w/:%#\$&\?\(\)~\.=\+\-]+", url): print("これはURLの可能性があります") else: print("これはURLではありません")○実行結果

先程同様matchメソッドを使っています。
URLは「https?://[\w/:%#\$&\?()~.=+-]+」というパターンに、マッチするかどうかで判定できます。
このように正規表現を使えば、URLのような複雑な文字列も判定できるのです。
まとめ
本記事ではPythonの正規表現について解説しました。
正規表現のやり方の基本がお分かり頂けたでしょうか?
URLを調べる方法などは少し難しいかもしれませんが、正規表現の便利さは分かったかと思います。
正規表現でややこしいのは、re モジュールのメソッドの使い方です。
本記事で紹介したコード例を参考に、メソッドの使い方を確認してみてください。
次回は例外処理の方法について解説します。



コメント