

中級編では、PythonでWebページをスクレイピングする方法を解説します。
今回はその段一段階として、Webページを取得してそのまま表示する方法を解説しましょう。
スクレイピングの最も基本となる部分なので、やり方をしっかり覚えてくださいね。
なお、なるべく初心者にも分かりやすいように解説しますが、もし分からない部分がある場合、入門編、初級編をおさらいするのをおすすめします。
【入門編1】Pythonのインストール、環境構築方法を4Stepで解説!
スクレイピングとは?
Webページの情報を取得する技術を、スクレイピングと呼びます。
取得した情報をエクセルなどに整理することで、様々なことに活用可能です。
たとえば、プレゼン資料に添付する情報として使うなど。
他にも、市場動向などをリアルタイムで把握したり、競合他社の商品の価格を調査したり、といったことが可能です。
Webページというのは、毎日更新されている場合も多いです。
たとえば、Yahoo!ニュースなどでは随時新しいニュースが投稿されていますね。
そのため、手動でWebページの情報をまとめる場合、更新される度に、サイトに行って、コピーして……を繰り返す必要があり、非常に手間です。
そういった面倒な単純作業は、Pythonにまかせてしまえば良いのです。
Windowsの「タスクスケジューラ」などを使って、プログラムを毎日決まった時間に動かせば、作業が楽になります。
スクレイピングのやり方を覚えると、プログラミングの便利さが実感できるため、初学者の方はやり方を覚えて欲しいです。
Webページのデータを取得する手順
それではWebページのデータを取得する、具体的な方法を解説しましょう。
以下のStepに分けて解説します。
- Step1.requestsをimportする
- Step2.Getメソッドを使う
- Step3.Webページを表示する
少し難しいかもしれませんが、その分1つのStepを丁寧に解説するので、ご心配なく
コード例もあるので、実際に動かしながらやり方を覚えていきましょう。
Step1.requestsをimportする
Webページのデータを取得する場合、requestsモジュールを使う必要があります。
モジュールとは、複数のプログラムを1つにしたもののことで、他のプログラムから呼び出すことで利用可能です。
モジュールを活用することで、組み込み関数ではできない高度な操作ができます。
モジュールに関して詳しく知りたい方は、【初級編10】pythonの標準ライブラリ一覧を紹介!を読んでください。
requestsモジュールをimportするときは、ソースコードの上に次のように記述しましょう。
○コード例
import requests #requestsモジュールをimportrequestsはPythonの標準ライブラリであるため、特にファイルをインストールする必要もなく、import文を書くだけでOKです。
Step2.Getメソッドを使う
次にgetメソッドを使って、Webページを取得してみましょう。
メソッドとは、オブジェクトの操作を定義したもので、データの型と引数を指定することで使えます。
メソッドに関して詳しく知りたい方は、【初級編8】pythonのメソッドと関数の違いを理解しようを読んでください。
関数と似たようなものですが、厳密に言うと概念が異なります。
requestsモジュールにはいくつかのメソッドがあり、getメソッドは次のように使います。
○コード例
import requests #requestsモジュールをimport site_data = requests.get("https://news.yahoo.co.jp/") #getメソッドでYahoo!ニュースを取得getメソッドの引数に、「取得したWebページのURL」を記入しましょう。
こうすることで、そのページのデータを取得できます。
取得されたデータは、「site_data」という変数にここでは格納しています。
今回は例として「Yahoo!ニュース」のサイトを取得してみましたが、自サイトを持っている方はぜひそちらも取得してみましょう。
Step3.Webページを表示する
getメソッドを使ったら、後はそれをprintで表示するだけです。
ここでは取得したWebページを何もいじらずそのまま表示してみます。
○コード例
import requests #requestsモジュールをimport site_data = requests.get("https://news.yahoo.co.jp/") #getメソッドでヤフーニュースサイトを取得 print(site_data.text) #「.text」でHTMLを丸ごと取得○実行結果
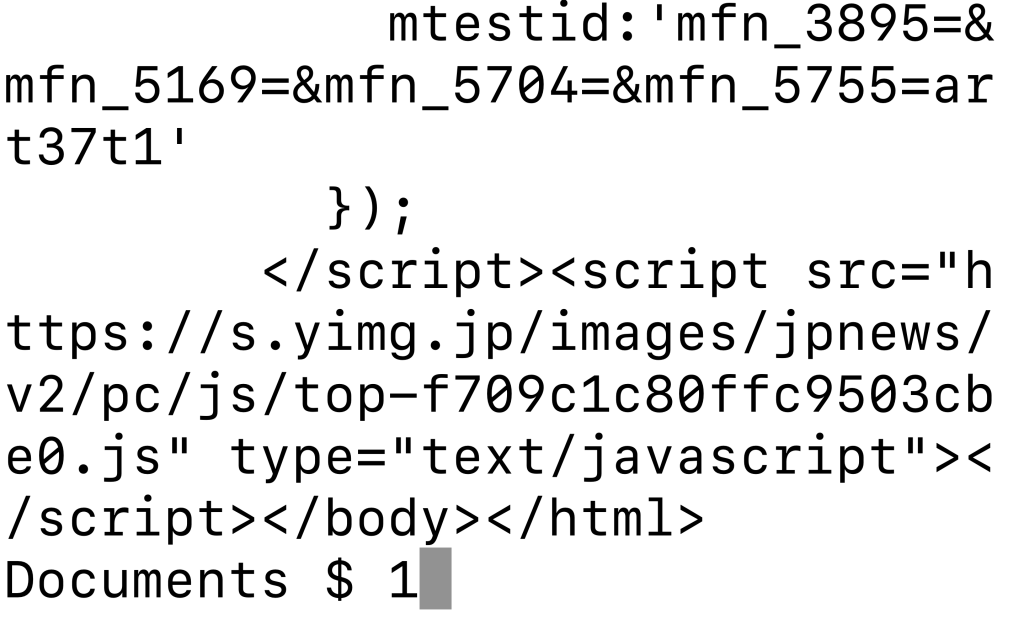
Webページの中身を表示する場合「.text」をつける必要があります。
「.text」をつけないと正しく表示されないので、気をつけましょう。
実行結果を見て分かる通り、WebページのHTMLがずらっと表示されています。
これはヤフーニュースのHTMLになります。
以上がPythonでWebページを取得する基本的な流れとなります。
まとめ
本記事では、PythonでWebページを取得する方法を解説しました。
requestsモジュールの意味やgetメソッドの使い方が、お分かりいただけたかと思います。
スクレイピングを行うことで、Webページのデータを取り出し、様々なことに活用できます。
今回はWebページを丸ごと表示させただけで、もちろんこれではプレゼン資料に使うなどはできません。
そこで、取得したデータを整理し、活用できるようにしていく必要があります。
次回は、取得したデータをHTMLファイルに保存する方法を解説しましょう。



コメント