

今回は、PythonでWebページの様々な情報を抜き出す方法を解説します。
今まではWebページのデータを丸ごと表示していましたが、本記事を読むことで、一部分のみを表示できます。
これができれば一気に実用的なスクレイピングに近づきます。
ぜひやり方を覚えてみてくださいね。
Webページから情報を抜き出すには、BeautifulSoupモジュールが必要
BeautifulSoupとは、HTMLデータを解析するためのモジュールです。
このモジュールを使うことで、簡単にHTMLからデータを取り出すことができます。
モジュールに関して詳しく知りたい方は、【初級編10】pythonの標準ライブラリ一覧を紹介!を読んでください。
もちろん、使わなくても正規表現を使えばできるのですが、それだと大変なので、BeautifulSoupを使うのをおすすめします。
BeautifulSoupモジュールを使う場合、以下のようにソースの冒頭にimport文を記述してください。
○コード例
from bs4 import BeautifulSoupこれでBeautifulSoupモジュールが使えるようになりました。
Pythonで様々なデータを抜き出す方法
PythonでHTMLから、様々なデータを抜き出す方法をご紹介しましょう。
以下の項目に分けて、やり方を解説します。
- タイトルを抜き出す
- リンクを抜き出す
- 特定のクラスを抜き出す
タイトルを抜き出す
まず、HTMLからタイトル部分だけを抜き出す方法を解説しましょう。
Webページには必ずタイトルが付けられています。
タイトルは「title」というタグを使って記入されています。
タイトルを抜き出すには次のように記述します。
○コード例
import requests from bs4 import BeautifulSoup site_data = requests.get("https://news.yahoo.co.jp/") soup = BeautifulSoup(site_data.text, 'html.parser') print(soup.title)○実行結果
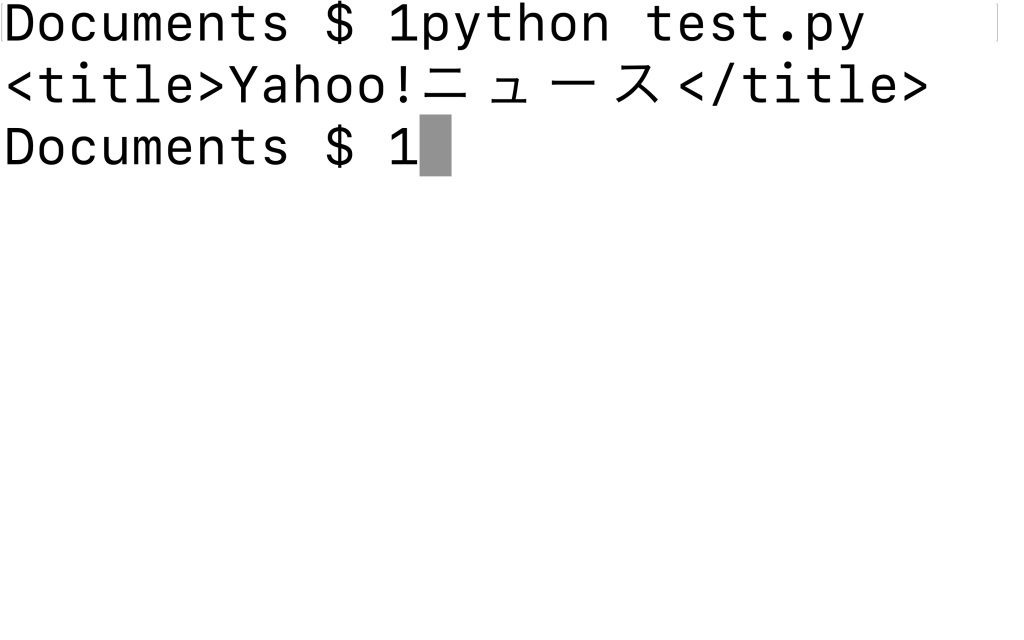
まず、いつもどおりgetメソッドでWebページを取得します。
BeautifulSoupメソッドで、HTMLを解析します。
第一引数に解析したいHTML、第二引数に「’html.parser’」を記入することが可能です。
解析が完了したら「.title」を付けることで、タイトルのみを表示できます。
ただ、これだとタイトルタグも一緒に表示されていますね。
そこで、タグを除外する方法も紹介しましょう。
○コード例
import requests from bs4 import BeautifulSoup site_data = requests.get("https://news.yahoo.co.jp/") soup = BeautifulSoup(site_data.text, 'html.parser') print(soup.title.string)○実行結果
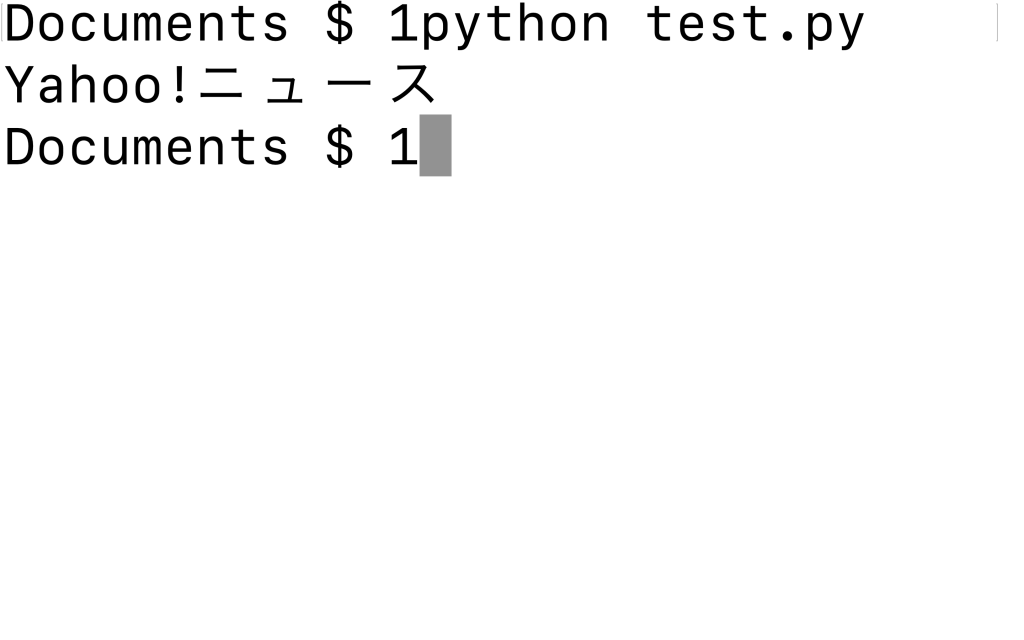
上記のように「.string」を付けると、タグが除外されます。
リンクを抜き出す
つづいて、リンクを抜き出す方法を解説しましょう。
HTMLでリンクを表す場合、a href~と記述します。
そのため、a要素をHTMLから抜き出せばよいのです。
○コード例
import requests from bs4 import BeautifulSoup site_data = requests.get("https://news.yahoo.co.jp/") soup = BeautifulSoup(site_data.text, 'html.parser') print(soup.find("a"))○実行結果
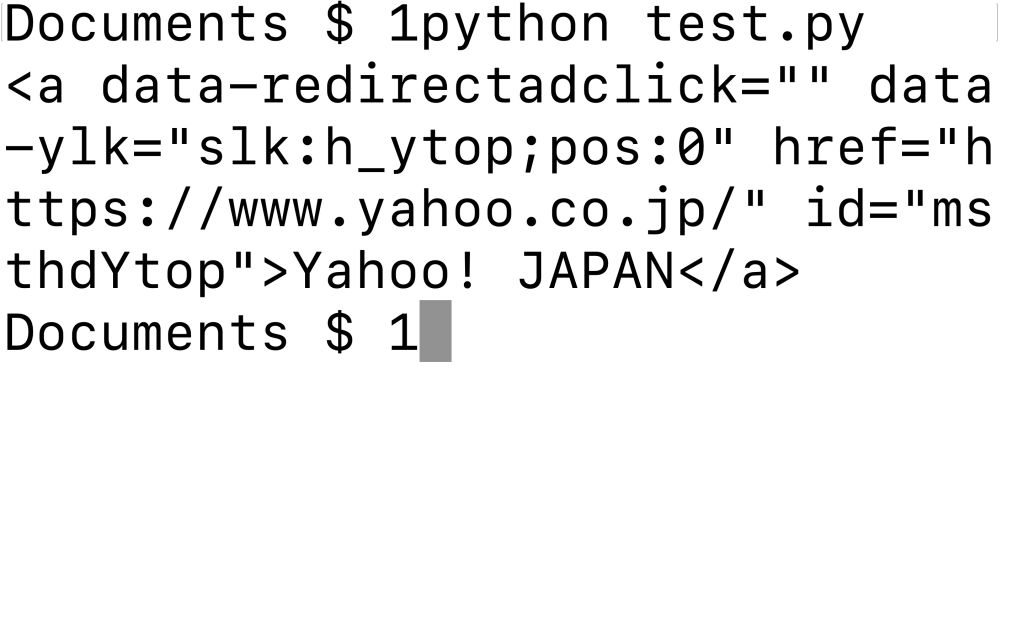
HTMLから特定の要素を抜き出す場合は、findメソッドを使います。
findメソッドで「a」を指定することで、a要素のみが抜け出せるため、リンクのみが取り出せます。
こちらも先程同様「.string」を付ければ、タグの中身だけが出力されます。
findメソッドは、1番最初の要素のみを取り出します。
全ての要素を取り出す場合は、find_allメソッドを使います。
○コード例
import requests from bs4 import BeautifulSoup site_data = requests.get("https://news.yahoo.co.jp/") soup = BeautifulSoup(site_data.text, 'html.parser') print(soup.find_all("a"))○実行結果

これでHTML内全てのリンクを取り出すことに成功しました。
特定のクラスを抜き出す
最後にHTMLから指定したclass属性のみを抜き出す方法を解説します。
特定のクラスを抜き出す場合は、selectメソッドを使います。
○コード例
import requests from bs4 import BeautifulSoup site_data = requests.get("https://news.yahoo.co.jp/") soup = BeautifulSoup(site_data.text, 'html.parser') print(soup.select(".logo"))○実行結果

上記の例ではselectメソッドによって、「class=”logo”」の部分のみが表示されています。
findメソッドとselectメソッドは良く使うので、一緒に覚えておきましょう。
findメソッドが特定の要素を取り出すのに対し、selectメソッドは特定のクラスを取り出します。
まとめ
本記事では、Webページから様々なデータを取り出す方法を解説しました。
findメソッドやselectメソッド、「.title」、「.string」などの使い方がお分かり頂けたかと思います。
BeautifulSoupモジュールを使うことで、HTMLを解析でき、簡単にHTMLの一部を抜き出すことが可能です。
次回は、抜き出したデータをテキストにまとめる、という本格的なスクレイピングのやり方をみていきましょう。



コメント